4.5. Organisatie van schijven
De kleinste vorm van organisatie die FreeBSD gebruikt om bestanden te vinden is de bestandsnaam. Bestandsnamen zijn hoofdlettergevoelig, wat betekent dat readme.txt en README.TXT twee verschillende bestanden zijn. FreeBSD gebruikt de extensie niet (.txt) van een bestand om te bepalen of het bestand een programma, een document of een vorm van data is.
Bestanden worden bewaard in mappen. Een map kan leeg zijn of honderden bestanden bevatten. Een map kan ook andere mappen bevatten, wat het mogelijk maakt om een hiërarchie van mappen te maken. Dit maakt het veel makkelijker om data te organiseren.
Bestanden en mappen worden aangegeven door het bestand of de map aan te geven, gevolgd door een voorwaardse slash, /, gevolgd door andere mapnamen die nodig zijn. Als map foo de map bar bevat, die op zijn beurt het bestand readme.txt bevat, dan wordt de volledige naam of pad naar het bestand foo/bar/readme.txt.
Mappen en bestanden worden bewaard op een bestandssysteem. Elk bestandssysteem bevat precies één map op het hoogste niveau die de rootmap van het bestandssysteem heet. Deze rootmap kan op zijn beurt andere mappen bevatten.
Tot zover is dit waarschijnlijk hetzelfde als voor elk ander besturingssysteem. Er zijn een paar verschillen. MS-DOS® gebruikt bijvoorbeeld een \ om bestanden en mappen te scheiden, terwijl Mac OS® gebruik maakt van :.
FreeBSD gebruikt geen schijfletters, of andere schijfnamen in het pad. FreeBSD gebruikt geen c:/foo/bar/readme.txt.
Eén bestandssysteem wordt aangewezen als root bestandssysteem, waar naar wordt verwezen met /. Elk ander bestandssysteem wordt daarna gekoppeld onder het root bestandssysteem. Hoeveel schijven er ook aan een FreeBSD systeem hangen, het lijkt alsof elke map zich op dezelfde schijf bevindt.
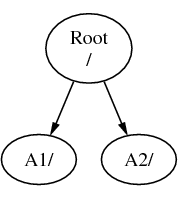
Stel er zijn drie bestandssystemen met de namen A,B en C. Elk bestandssysteem heeft één root map die twee andere mappen bevat, A1 en A2 (zo ook voor de andere twee: B1, B2, C1 en C2).
A wordt het root besturingsysteem. Met ls, dat de inhoud van de map kan tonen, zijn de twee mappen A1 en A2 te zien. De mappenstructuur ziet er als volgend uit:
Een bestandssysteem moet gekoppeld worden in een map op een ander bestandssysteem. Als nu bestandssysteem B wordt gekoppeld onder de map A1 vervangt B A1 en zien de koppelingen in B er als volgt uit:
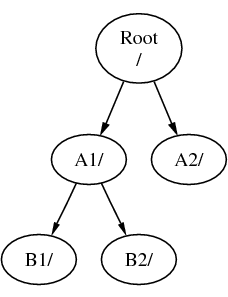
Elk bestand dat in de mappen B1 en B2 aanwezig is, kan benaderd worden met het pad /A1/B1 of /A1/B2. Elk bestand dat in /A1 stond is tijdelijk verborgen en komt tevoorschijn als Bis ontkoppeldvan A.
Als B gekoppeld is onder A2 ziet de diagram er als volgt uit:
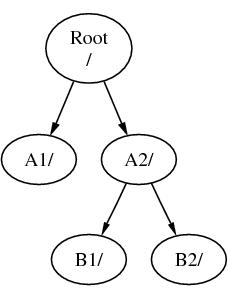
en de paden zouden dan respectievelijk /A2/B1 en /A2/B2 zijn.
Bestandssystemen kunnen op elkaar worden gekoppeld. Doorgaand op het vorige voorbeeld kan het bestandssysteem C gekoppeld worden bovenop de map B1 in het bestandssysteem B. Dit resulteert in:
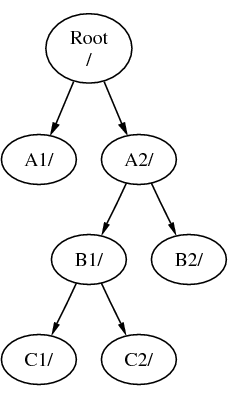
Of C kan direct onder het bestandssysteem A gekoppeld worden, onder de map A1:
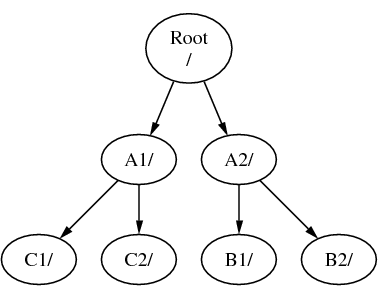
Hoewel het niet gelijk is, lijkt het op het gebruik van join in MS-DOS.
Beginnende gebruikers hoeven zich hier gewoonlijk niet mee bezig te houden. Normaal gesproken worden bestandssystemen gemaakt als FreeBSD wordt geïnstalleerd en er wordt besloten waar ze gekoppeld worden. Meestal worden ze ook niet gewijzigd tot er een nieuwe schijf aan een systeem wordt toegevoegd.
Het is mogelijk om één groot root bestandssysteem te hebben en geen andere. Deze benadering heeft voordelen en nadelen.
Voordelen van meerdere bestandssystemen
-
Verschillende bestandssystemen kunnen verschillende mount opties hebben. Met een goede voorbereiding kan het root bestandssysteem bijvoorbeeld als alleen-lezen gekoppeld worden, waardoor het onmogelijk wordt om per ongeluk kritische bestanden te verwijderen of te bewerken. Het scheiden van andere bestandssystemen die beschrijfbaar zijn door gebruikers, zoals /home van andere bestandssystemen stelt de beheerder in staat om ze nosuid te koppelen. Deze optie voorkomt dat suid/guid bits op uitvoerbare bestanden effectief gebruikt kunnen worden, waardoor de beveiliging mogelijk beter wordt.
-
FreeBSD optimaliseert automatisch de layout van bestanden op een bestandssysteem, afhankelijk van hoe het bestandssysteem wordt gebruikt. Een bestandsysteem dat veel bestanden bevat waar regelmatig naar geschreven wordt, wordt anders geoptimaliseerd dan een bestandssysteem dat minder maar grotere bestanden bevat. Door het gebruik van één groot bestandssysteem werkt deze optimalisatie niet.
-
FreeBSD's bestandssystemen zijn erg robuust als er bijvoorbeeld een stroomstoring is, hoewel een stroomstoring op een kritiek moment nog steeds kan leiden tot schade aan de structuur van het bestandssysteem. Door het verdelen van data over meerdere bestandssystemen, is de kans groter dat het systeem nog opstart, wat terugzetten van een back-up makkelijker maakt als dat nodig is.
Voordeel van één bestandssysteem
-
Bestandssystemen hebben een vaste grootte. Als bij de installatie van FreeBSD een bestandssysteem wordt gemaakt, is het later mogelijk dat de partitie groter gemaakt moet worden. Dit is niet zo makkelijk zonder een back-up, het opnieuw maken van het bestandssysteem met gewijzigde grootte en het terugzetten van de geback-upte gegevens.
Belangrijk: FreeBSD heeft growfs(8) waarmee de grootte van het bestandssysteem is aan te passen terwijl het draait.
Bestandssystemen worden opgeslagen in partities. Dit betekent niet hetzelfde als de algemene betekenis van de term partitie (bijvoorbeeld, MS-DOS partitie), vanwege FreeBSD's UNIX® achtergrond. Elke partitie wordt geïdentificeerd door een letter van a tot en met h. Elke partitie kan slechts één bestandssysteem hebben, wat betekent dat bestandssystem vaak omschreven worden aan de hand van hun koppelpunt in de bestandssysteem hiërarchie of de letter van de partitie waar ze in opgeslagen zijn.
FreeBSD gebruikt ook schijfruimte voor wisselbestanden. Wisselbestanden geven FreeBSD virtueel geheugen. Dit geeft de computer de mogelijkheid om net te doen alsof er veel meer geheugen in de machine aanwezig is dan werkelijk het geval is. Als FreeBSD geen geheugen meer heeft, verplaatst het data die op dat moment niet gebruikt wordt naar de wisselbestanden en plaatst het terug als het wel nodig is (en zet iets anders in ruil daarvoor terug).
Aan sommige partities zijn bepaalde conventies gekoppeld.
| Partitie | Conventie |
|---|---|
| a | Bevat meestal het root bestandssysteem |
| b | Bevat meestal de swapruimte |
| c | Heeft meestal dezelfde grootte als de hele harde schijf. Dit geeft hulpprogramma's de mogelijkheid om op een complete schijf te werken (voor bijvoorbeeld een bad block scanner) om te werken op de c partitie. Meest wordt hierop dan ook geen bestandssysteem gecreeërd. |
| d | Partitie d had vroeger een speciale betekenis, maar die is verdwenen. d zou nu kunnen werken als een normale partitie. |
Elke partitie die een bestandssysteem bevat is opgeslagen in wat FreeBSD noemt een slice. Slice is FreeBSD's term voor wat meeste mensen partities noemen. Dit komt wederom door FreeBSD's UNIX achtergrond. Slices zijn genummerd van 1 tot en met 4.
Slicenummers volgen de apparaatnamen, voorafgegaan door een s die begint bij 1. Dus “da0s1” is de eerste slice op de eerste SCSI drive. Er kunnen maximaal vier fysieke slices op een schijf staan, maar er kunnen logische slices in fysieke slices van het correcte type staan. Deze uitgebreide slices zijn genummerd vanaf 5. Dus “ad0s5” is de eerste uitgebreide slice op de eerste IDE schijf. Deze apparaten worden gebruikt door bestandssystemen waarvan verwacht wordt dat ze een slice in beslag nemen.
Slices, “gevaarlijk toegewijde” (dangerously dedicated) fysieke drivers en andere drives bevatten partities, die worden weergegeven door letters vanaf a tot h. Deze letter wordt achter de apparaatnaam geplakt. Dus “da0a” is de a partitie op de eerste da drive, die “gevaarlijk toegewijd” is. “ad1s3e” is de vijfde partitie op de derde slice van de tweede IDE schijf.
Elke schijf op het systeem wordt geïdentificeerd. Een schijfnaam start met een code die het type aangeeft en dan een nummer dat aangeeft welke schijf het is. In tegenstelling tot bij slices, start het nummeren van schijven bij 0. Standaardcodes staan beschreven in Tabel 4-1.
Bij een referentie aan een partitie verwacht FreeBSD ook dat de slice en schijf refereert naar die partitie en als naar een slice wordt verwezen moet ook de schijfnaam genoemd worden. Dit kan door de schijfnaam, s, het slice nummer en de partitieletter aan te geven. Voorbeelden staan in Voorbeeld 4-1.
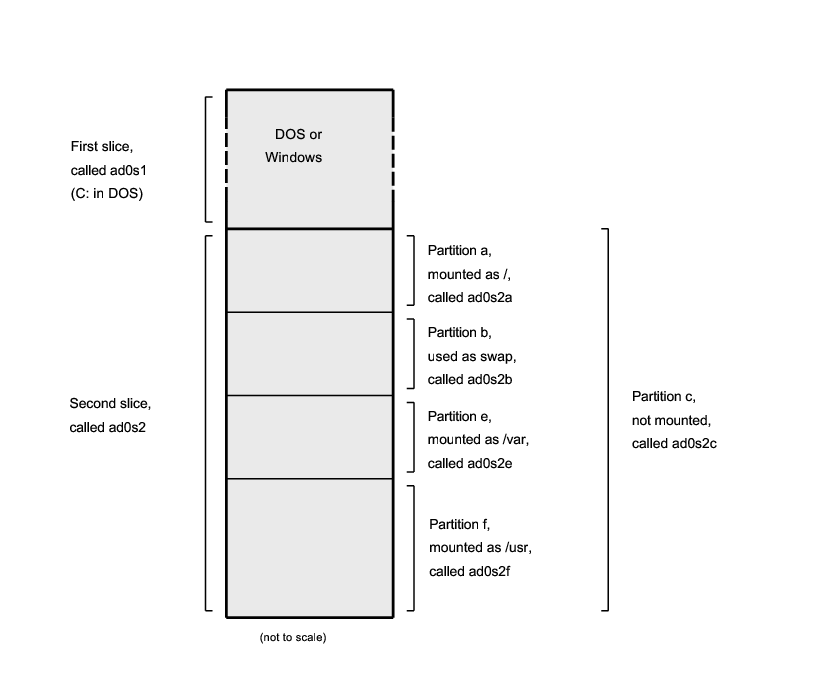
In Voorbeeld 4-2 staat een conceptmodel van een schijflayout die een en ander verduidelijkt.
Voordat FreeBSD geïnstalleerd kan worden moeten eerst de schijfslices gemaakt worden en daarna moeten de partities op de slices voor FreeBSD gemaakt worden. Daarna wordt op elke partitie het bestandssysteem (of wisselbestand) gemaakt en als laatste wordt besloten waar het filesysteem gekoppeld wordt.
Tabel 4-1. Schijf apparaatcodes
| Code | Betekenis |
|---|---|
| ad | ATAPI (IDE) schijf |
| da | SCSI directe toegang schijf |
| acd | ATAPI (IDE) CDROM |
| cd | SCSI CDROM |
| fd | Floppydisk |
Voorbeeld 4-2. Conceptmodel van een schijf
Het onderstaande diagram geeft aan hoe FreeBSD de eerste IDE schijf in het systeem ziet. Stel dat de schijf 4 GB groot is en dat deze twee 2 GB slices (MS-DOS partities) bevat. De eerste slice bevat een MS-DOS schijf, C: en de tweede slice bevat een FreeBSD installatie. Deze FreeBSD installatie heeft drie partities en een partitie met een wisselbestand.
De drie partities hebben elk een bestandssysteem. Partitie a wordt gebruikt voor het root bestandssysteem, e voor de map /var en f voor de map /usr.