2 VM Objects
The best way to begin describing the FreeBSD VM system is to look at it from the perspective of a user-level process. Each user process sees a single, private, contiguous VM address space containing several types of memory objects. These objects have various characteristics. Program code and program data are effectively a single memory-mapped file (the binary file being run), but program code is read-only while program data is copy-on-write. Program BSS is just memory allocated and filled with zeros on demand, called demand zero page fill. Arbitrary files can be memory-mapped into the address space as well, which is how the shared library mechanism works. Such mappings can require modifications to remain private to the process making them. The fork system call adds an entirely new dimension to the VM management problem on top of the complexity already given.
A program binary data page (which is a basic copy-on-write page) illustrates the complexity. A program binary contains a preinitialized data section which is initially mapped directly from the program file. When a program is loaded into a process's VM space, this area is initially memory-mapped and backed by the program binary itself, allowing the VM system to free/reuse the page and later load it back in from the binary. The moment a process modifies this data, however, the VM system must make a private copy of the page for that process. Since the private copy has been modified, the VM system may no longer free it, because there is no longer any way to restore it later on.
You will notice immediately that what was originally a simple file mapping has become
much more complex. Data may be modified on a page-by-page basis whereas the file mapping
encompasses many pages at once. The complexity further increases when a process forks.
When a process forks, the result is two processes—each with their own private
address spaces, including any modifications made by the original process prior to the
call to fork(). It would be silly for the VM system to make
a complete copy of the data at the time of the fork()
because it is quite possible that at least one of the two processes will only need to
read from that page from then on, allowing the original page to continue to be used. What
was a private page is made copy-on-write again, since each process (parent and child)
expects their own personal post-fork modifications to remain private to themselves and
not effect the other.
FreeBSD manages all of this with a layered VM Object model. The original binary
program file winds up being the lowest VM Object layer. A copy-on-write layer is pushed
on top of that to hold those pages which had to be copied from the original file. If the
program modifies a data page belonging to the original file the VM system takes a fault
and makes a copy of the page in the higher layer. When a process forks, additional VM
Object layers are pushed on. This might make a little more sense with a fairly basic
example. A fork() is a common operation for any *BSD
system, so this example will consider a program that starts up, and forks. When the
process starts, the VM system creates an object layer, let's call this A:

A represents the file—pages may be paged in and out of the file's physical media as necessary. Paging in from the disk is reasonable for a program, but we really do not want to page back out and overwrite the executable. The VM system therefore creates a second layer, B, that will be physically backed by swap space:
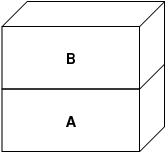
On the first write to a page after this, a new page is created in B, and its contents are initialized from A. All pages in B can be paged in or out to a swap device. When the program forks, the VM system creates two new object layers—C1 for the parent, and C2 for the child—that rest on top of B:
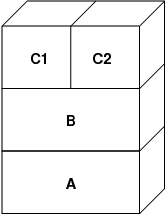
In this case, let's say a page in B is modified by the original parent process. The
process will take a copy-on-write fault and duplicate the page in C1, leaving the
original page in B untouched. Now, let's say the same page in B is modified by the child
process. The process will take a copy-on-write fault and duplicate the page in C2. The
original page in B is now completely hidden since both C1 and C2 have a copy and B could
theoretically be destroyed if it does not represent a “real” file; however,
this sort of optimization is not trivial to make because it is so fine-grained. FreeBSD
does not make this optimization. Now, suppose (as is often the case) that the child
process does an exec(). Its current address space is
usually replaced by a new address space representing a new file. In this case, the C2
layer is destroyed:
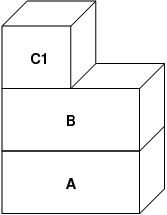
In this case, the number of children of B drops to one, and all accesses to B now go
through C1. This means that B and C1 can be collapsed together. Any pages in B that also
exist in C1 are deleted from B during the collapse. Thus, even though the optimization in
the previous step could not be made, we can recover the dead pages when either of the
processes exit or exec().
This model creates a number of potential problems. The first is that you can wind up with a relatively deep stack of layered VM Objects which can cost scanning time and memory when you take a fault. Deep layering can occur when processes fork and then fork again (either parent or child). The second problem is that you can wind up with dead, inaccessible pages deep in the stack of VM Objects. In our last example if both the parent and child processes modify the same page, they both get their own private copies of the page and the original page in B is no longer accessible by anyone. That page in B can be freed.
FreeBSD solves the deep layering problem with a special optimization called the “All Shadowed Case”. This case occurs if either C1 or C2 take sufficient COW faults to completely shadow all pages in B. Lets say that C1 achieves this. C1 can now bypass B entirely, so rather then have C1->B->A and C2->B->A we now have C1->A and C2->B->A. But look what also happened—now B has only one reference (C2), so we can collapse B and C2 together. The end result is that B is deleted entirely and we have C1->A and C2->A. It is often the case that B will contain a large number of pages and neither C1 nor C2 will be able to completely overshadow it. If we fork again and create a set of D layers, however, it is much more likely that one of the D layers will eventually be able to completely overshadow the much smaller dataset represented by C1 or C2. The same optimization will work at any point in the graph and the grand result of this is that even on a heavily forked machine VM Object stacks tend to not get much deeper then 4. This is true of both the parent and the children and true whether the parent is doing the forking or whether the children cascade forks.
The dead page problem still exists in the case where C1 or C2 do not completely overshadow B. Due to our other optimizations this case does not represent much of a problem and we simply allow the pages to be dead. If the system runs low on memory it will swap them out, eating a little swap, but that is it.
The advantage to the VM Object model is that fork() is
extremely fast, since no real data copying need take place. The disadvantage is that you
can build a relatively complex VM Object layering that slows page fault handling down a
little, and you spend memory managing the VM Object structures. The optimizations FreeBSD
makes proves to reduce the problems enough that they can be ignored, leaving no real
disadvantage.